Estimating Reproducibility of AI Research
There are a number of different ways to refer to reproducibility, in this piece we are actually referring to replicability using the standard ACM definition. It refers to research that reuses the data and/or analysis to hopefully get the same results. To this end, replication is considered to be a cornerstone of wider scientific reproducibility where multiple different studies should attain the same results. Concerns have been raised about the ease of replicating results of AI papers. Making replication easier will help to raise public confidence in the field.
Why is the replication of research reported in a paper so difficult?
For AI, many factors affect their replicability. It is difficult to replicate a study as it requires access to and operational knowledge of software, data, specific settings (hyper parameters) and more. Another contributing factor is not technical but social: there is little incentive to spend time replicating someone else’s research. Researchers get no scientific credit for it and it costs time and uses resources while not contributing to their next promotion.
While making the process of replication easier would be ideal, some indication of how replicable a published study is without actually having to replicate it, would already help. This is where various initiatives within the AI and wider computer science community are exploring how AI studies can be made more replicable.
Determining the replicability of AI
During O. E. Gundersen’s recent talks at the AAAI; Reproducibility of AI workshop and, Evaluating Evaluation of AI Systems (Meta-Eval 2020), he provided a high level overview of methods used in AI research (Table 1).
Table 1

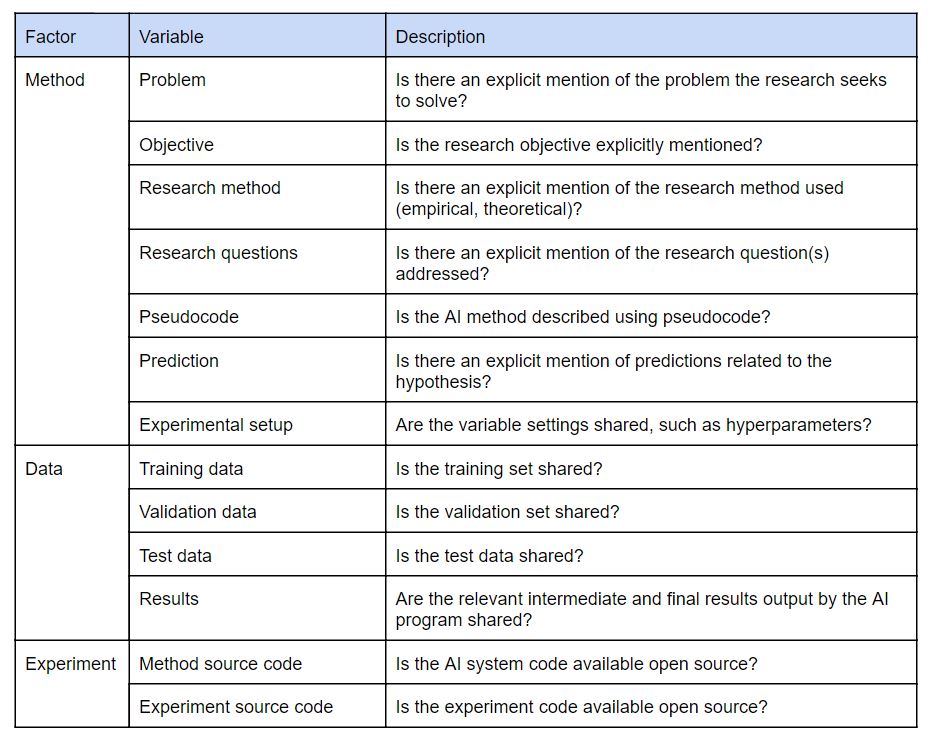
Furthermore, Gundersen discussed the current state of replicability of AI research. One of his experiments investigated whether the presence of specific sections of a research paper could be used as a proxy to determine it’s replicability by classifying certain information in the methods, experiments and the data, see Table 2.
Table 2
O.E. Gundersen and Sigbjørn Kjensmo sampled 400 papers, 100 papers from each installment of AAAI 2014, AAAI 2016, IJCAI 2013 and IJCAI 2016, and assessed the documentation provided by each study, see Figure 1.
Figure 1

Table 3

O.E. Gundersen and Sigbjørn Kjensmo then sampled 30 of the most highly cited papers of these 400 based on Scopus data. They tried to replicate 22 papers after having filtered out those containing only a method section (R3 papers, see Table 3), and spent a maximum of 40 hours per paper. Categories of results after the expended effort were that they:
- 20% Successfully replicated the research
- 13% Achieved partial success
- 23% Failed
- 17% Obtained no result
- 27% Were filtered out due to lack of data and experimental information
The top six aspects of failure identified were:
- Aspect of implementation not described or ambiguous (R2)
- Aspect of experiment not described or ambiguous (R2)
- Not all hyper-parameters are specified (R2)
- Mismatch between data in paper and available online (R1+R2)
- Method code shared; experiment code not shared (R1)
- Method not described with sufficient detail (R2)
Given the increasing speed with which new AI systems and techniques are developed, an automated measure for assessing the quality of a research result is likely to increase the confidence in published research results. Just as international bodies develop quality standards in many fields, understanding which AI studies are likely to be replicable is a first step towards the development of quality standards in AI. O.E. Gundersen’s research provides us with a useful, automated means of assessing replicability- which itself will be fraught with the unavoidable false negatives and positives. The importance of documentation in this process may help the AI community in maturing the culture around completeness to help the replicability, and therefore confidence, in the AI field.
References
Reproducibility vs. Replicability: A Brief History of a Confused Terminology, Hans E. Plesser, Front. Neuroinform., 18 Jan 2018 https://doi.org/10.3389/fninf.2017.00076
O. E. Gundersen’s presentation: https://folk.idi.ntnu.no/odderik/presentations/20200208-MetaEval-Keynote.pdf
O. E. Gundersen and Sigbjørn Kjensmo. “State of the art: Reproducibility in artificial intelligence.” Thirty-second AAAI conference on artificial intelligence. 2018. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewFile/17248/15864
O. E. Gundersen, Yolanda Gil, and David W. Aha. “On reproducible AI: Towards reproducible research, open science, and digital scholarship in AI publications.” AI magazine 39.3 (2018): 56-68. https://doi.org/10.1609/aimag.v39i3.2816
O. E. Gundersen (2019). Standing on the Feet of Giants — Reproducibility in AI. AI Magazine, 40(4), 9-23. DOI:https://doi.org/10.1609/aimag.v40i4.5185
R. Isdahl and O. E. Gundersen, “Out-of-the-Box Reproducibility: A Survey of Machine Learning Platforms,” 2019 15th International Conference on eScience (eScience), San Diego, CA, USA, 2019, pp. 86-95. DOI:
10.1109/eScience.2019.00017