Linked Data Innovation for a Smarter Government
Today is Prinsjesdag, the day that the Miljoenennota, the Dutch government’s yearly national budget is published. This budget determines how government funds will be allocated to achieve societal goals in the coming year. The Miljoenennota initiates the budget implementation cycle which consists of various phases: spending, adjusting, auditing and reporting. During this cycle, the Dutch Ministry of Finance must pull together a multitude of reports, or information products. These products are created in several data workflows that combine detailed financial information originating from various government sources. These data workflows involve specific business logic which requires detailed domain knowledge to be applied precisely. In the past, many steps in this workflow consisted of manual data copying operations and implicit knowledge available only in the heads of experts. As a result, the workflow could not be automatically repeated or validated. Triply and the Ministry of Finance are now working on a proof-of-concept to implement increasingly larger parts of this workflow using linked data. This allows data to be interchanged, combined, processed, and validated in increasingly repeatable and automated ways.Adding meaning to data
When data is stored in traditional databases, the meaning of the data is encoded within the database’s schema. However, these dataset schemas cannot be easily shared across databases. Since traditional databases use a dedicated schema, the meaning of the data remains local to that database. Where complex organizations use hundreds of databases, their information is effectively dispersed over a large number of isolated data silos. Triply’s approach to data integration is to use a global schema, or ontology, to encode the meaning of data in a way that can be shared among databases. With the help of TriplyDB, the Ministry of Finance is creating a standardized ontology of national budget concepts. For example, the ontology distinguishes commitments to future payments from payment transactions. In traditional databases, the distinction between commitments and transactions must be enforced by the database user. This requires knowledgeable users, and even knowledgeable users can accidentally exchange commitments for transactions, resulting in incorrect reports. By using an ontology, the system is aware that the commitment amount is conceptually different from the transaction amount and can warn the user. By storing information in line with this national budget ontology, the Ministry can automatically integrate financial information from different government agencies without alignment mistakes. Secondly, since the ontology encodes the meaning of the key financial concepts and the constraints they must adhere to, the validity of the financial information can be verified automatically. Lastly, the financial information can be combined with other information from different domains altogether, offering more insights to both the public as well as the financial professional. This opens up interesting applications such as label-based budgeting: for instance, ‘green budgeting’ or ‘gender budgeting’.Back to the source
Storing financial information in linked data allows information to be traced throughout the entire budgetary workflow. For example, a number that is published in a cell of a table in the Miljoenennota can be traced back to the very calculation that produced it. The calculation itself can be traced back to the source data on which it was based. Within an organization this workflow can be traced across datasets and across processing tools. The figure 1 shows a diagrammatic overview of some of these relationships. The high-level workflow relationships are standardized in the international PROV [1] linked data ontology. Because linked data uses universal identifiers, it can even be traced across organizations. When organizational boundaries are crossed this must of course occur in a secure way, using secure web-based protocols.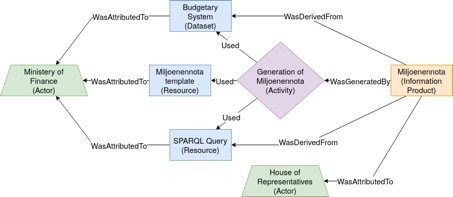 Figure 1: Derivation of the Miljoenennota information product using linked data.
Figure 1: Derivation of the Miljoenennota information product using linked data.