IoT as an enabler of AI: Revolutionizing fish production
The Internet of Things (IoT) is a hardware/software ecosystem that includes the ‘things’ side, typically composed of network-enabled sensors (light, temperature, distance), which connect and exchange data with actors (motors, servos, heaters, pumps). This technology enables AI by providing a constant stream of real-time or historical data while assuring its quality. This particular process ensures that AI applications achieve optimal results when solving data-driven problems. Applying AI in remote areas where continuous connection to the internet is not guaranteed requires that AI solutions have to be scalable and fail-safe to avoid data loss and provide consistent performance.The Internet of Fish
The marine environment is suffering from unsustainable fishing practices. Traditional aquaculture is not an environmentally friendly alternative, as most methods do not completely separate themselves from the natural environment, thus continuing to impact the surrounding marine ecosystem.
IoT Enables AI
IoT enables data collection to train AI models that balance the various input parameters. These are transmitted back to the actors to maintain an optimal state of the ecosystem. The IoT system consists of:- A hardware-software ecosystem;
- A software platform that manages the ‘things’ and the data they generate;
- Feedback loops that translate the analysed data into new input for the ’things’ (e.g., a higher target temperature based on school movement observations that indicate that the fish are affected by cold);
- A repository of data-based user applications such as dashboards for visualization or machine learning models for predictive maintenance.
Converting Data into Fish
Fish-farming is costly and labour-intensive. The BPE artificial ecosystem is completely automated and uses only a few resources, “manufacturing” fish independently of human intervention.
The Role of Domain Experts
Data scientists and AI experts alone can rarely be used to improve processes. Often it is the combination of domain knowledge (in BPE’s case, aquaculture experts), data scientists and enablers such as IoT that work together to tackle problems that previously seemed unsolvable. Knowing about how the data is collected and initially processed impacts the work of data scientists. For example, a machine that is switched off over the weekend might produce “anomalous” data on Monday mornings just because it needs to heat up first. Knowledge such as this can easily be gained by involving domain experts. If the project team cannot rely on the presence of domain experts then the amount of data that needs to be collected to achieve the same confidence is usually higher. By combining expertise from domain experts, such as BPE in fish farming, and technical expertise from Cloudflight, novel solutions can be found to critical human problems. In this case we can see an innovative and environmentally friendly solution to fish farming.Responsible Artificial Intelligence in Practice
The ECAAI Responsible AI Lab
The need for a responsible approach to AI has been recognized worldwide as reflected by the many manifestos and ethical guidelines that have been developed in the last few years [1]. The European Union for example, calls for Trustworthy AI [2] and defines a number of key requirements such as a need for human agency and oversight, transparency and accountability. But what does this mean in practice? How can practitioners who want to create trustworthy AI do so? That is the question driving the research of the Responsible AI Lab of the Amsterdam University of Applied Sciences (AUAS). The Responsible AI Lab is one of seven labs established by the Expertise Centre of Applied AI (ECAAI). The lab researches applied, responsible AI that empowers people and benefits society with a particular focus on the creative industries and the public domain.Understanding AI in context
Responsible AI means different things to different people. For us, responsible AI starts with the realization that AI systems impact people’s lives in both expected and unexpected ways. This is true for all technology, but what makes AI different is that a system can learn the rules that govern its behaviour and that this behaviour may change over time. In addition, many AI systems have a certain amount of agency to come to conclusions or actions without human interference. To better understand this impact, one needs to study an AI system in context and through experiment. Next to an understanding of the technology, this also requires an understanding of the application field and the involvement of the (future) users of the technology.AI is not neutral
There has been much attention on bias, unfairness and discrimination by AI systems, a recent example is the problem with face recognition on Twitter and Zoom. What we see here is that data mirrors culture, including prejudices, conscious and unconscious biases and power structures, and the AI picks up these cultural biases. So, bias is a fact of life, not just an artifact of some data set. The same holds for another form of bias, or rather subjectivity, that influences the impact an AI system may have: the many decisions, large and small, taken in the design and development process of such a system. Imagine for example a recommendation system for products or services, such as flights. The order in which the results are shown may influence the amount of clicks each receives and by that the profit of the competing vendors. Any choice made during the design process will have an effect, however small. Ideally, designers and developers reflect upon such choices during development. That in itself is difficult enough, but for AI systems that learn part of their behaviour from data, this is even more challenging.Tools for Responsible AI
To develop responsible AI systems worthy of our trust, practitioners need tools to [4]:- Understand and deal with the preexisting cultural bias that a system may pick up
- Reflect upon and deal with the bias introduced in the development process
- Anticipate and assess the impact an AI system has during deployment
Responsible AI research now
At ECAAI, and in particular in the Responsible AI Lab, we are doing research with practitioners from different domains to develop and evaluate all three types of tools: responsible AI algorithms, automated assessment tools and AI design methodologies. We want to ensure that the AI that surrounds us will be the AI we want to live with. For example, together with Dutch broadcasting organisations NPO and RTL and the Applied Universities of Rotterdam and Utrecht we are developing design tools for pluriform recommendation systems and for inclusive language processing. Furthermore, we are working with the City of Amsterdam to research how to guarantee inclusion and diversity in AI systems for recruitment. If you are interested in collaborating with the Responsible AI Lab, please contact: appliedai@hva.nl or p.wiggers@hva.nl.References
[1] See: https://aiethicslab.com/big-picture/ for an overview of AI principles developed worldwide. [2] Independent High-Level Expert Group on Artificial Intelligence (2019) Ethics Guideline for Trustworthy AI [4] The three sources of bias described here are based on: Batya Friedman & Helen Nissenbaum (1996). Bias in Computer Systems. ACM Transactions on Information Systems, Vol. 14(3), pp. 330-347. [5] See for examples of design patterns and assessment tools for example the projects of the The MozFest ‘building trustworthy AI working group’. https://www.mozillafestival.org/en/get-involved/building-trustworthy-ai-working-group/A Practitioner’s Perspective on Fairness in AI
The use of machine learning models to support decision making can have harmful consequences on individuals, particularly, when such models are used in critical applications in the social domain such as justice, health, education and resource allocation (e.g. welfare). These harms can be caused by different types of biases that can originate at any point of the algorithmic pipeline. In order to prevent discrimination and algorithmically reinforced bias, the Fair AI community has been developing best practices and new methods to ‘fix the bias’ in the data and therefore ensure fair outcomes.Fair AI: an active community
We encounter many “AI gone wrong” narratives in critical domains, ranging from hospital triage algorithms systematically discriminating against minorities¹, to welfare fraud detection algorithms that disproportionately fail among sub-populations². In response to these issues, fairness-driven solutions are emerging, for example, by deriving new algorithms that ensure fairness, or by identifying conditions under which certain fairness constraints can be guaranteed. New frameworks are also being developed to draw attention to best practices on how to avoid bias during the modelling process³. There are also a number of user-friendly tools⁴ that allow for testing a system against possible bias. Once bias is detected, it can be mitigated by either modifying the training data, or by constraining the inner-workings of machine learning algorithms to satisfy a given fairness definition, for example, ensuring that two groups get the same outcome distributions⁵.Ensuring Fair AI in practice is challenging
In our experience as practicing data scientists, the existing tools that deal with bias and ensuring fairness in machine learning suffer from an important limitation⁶: their validity and performance has been tested under unrealistic scenarios. Typically, the validity and performance of these solutions are tested on publicly available datasets such as COMPAS or the German credit datasets⁷ where the sources of bias are easily identifiable since they are linked to correlations with sensitive attributes such as gender, ethnicity, or age, which are available in the data sets. This means that the data can be corrected or the outcomes of a given model can be altered to fix the bias that originates from these correlations. In practice, sensitive attributes cannot be included directly in the modeling process, for legal or for confidentiality reasons, but other features that correlate with them might be used in the model, leading to indirect discrimination. These correlations can be unknown at the time of development, especially when sensitive attributes are missing. It is therefore challenging and sometimes impossible to apply fairness corrections in real-world models. Another challenge practitioners need to shoulder is that testing whether an algorithm is fair or not requires the knowledge of a desirable ground truth against which one can evaluate fairness of the outcomes. Furthermore, as practitioners, we need to acknowledge the broader context of high-impact decision making systems and for -ultimately- beneficial fairness interventions, we need to investigate the long-term impacts of these systems.The way forward
So what can we do to make fair AI achievable in practice? Mobilise the AI community to provide more realistic datasets. To achieve this, one approach is to facilitate (confidentiality-preserving) data exchange between industry and academia. Making relevant and realistic data sets available to the fair AI community will not only open new research avenues, it will also help create tangible solutions to fairness issues that can be used by practitioners, and consequently help solve the bias and discrimination issues. Encourage tackling some of the real-world challenges. Consider bias bounties⁸ where developers are offered monetary incentives to test the systems for bias in a similar way to the bug bounties offered in security software. Embrace inclusive communication between stakeholders and AI developers. Interpreting the real-world impact of an AI-driven solution can be challenging and requires open collaboration between the technical and functional teams throughout the AI lifecycle. We are undoubtedly living through crucial times in terms of developments in the fair AI field. In order to foster more fairness-enabling practices and to facilitate bridging the gap between theory and practice, we invite all interested readers to share their experiences, ideas and suggestions with us on this dedicated slack channel using the link below: https://join.slack.com/t/fair-ai/shared_invite/zt-edj2mqip-JZzmVGgduEjFiEpU3EXlyg We are building an inclusive community, whether you work for a company, startup or a university, whether you are a concerned citizen, policy or law expert, or a student interested in Fair AI, join us!References
- https://theappeal.org/politicalreport/algorithms-of-inequality-covid-ration-care/
- https://www.hrw.org/news/2019/11/08/welfare-surveillance-trial-netherlands
- https://cloud.google.com/inclusive-ml
- https://pair-code.github.io/what-if-tool/
- https://aif360.mybluemix.net/
- Note that we are not addressing here the more general issue of fixing an identified source of bias algorithmically, instead of addressing the actual societal issues leading to the bias, as we want to focus here on the province of the data scientists, in the real world.
- Popular fairness-datasets: http://www.fairness-measures.org/Pages/Datasets
- https://venturebeat.com/2020/04/17/ai-researchers-propose-bias-bounties-to-put-ethics-principles-into-practice/
Estimating Reproducibility of AI Research
There are a number of different ways to refer to reproducibility, in this piece we are actually referring to replicability using the standard ACM definition. It refers to research that reuses the data and/or analysis to hopefully get the same results. To this end, replication is considered to be a cornerstone of wider scientific reproducibility where multiple different studies should attain the same results. Concerns have been raised about the ease of replicating results of AI papers. Making replication easier will help to raise public confidence in the field.Why is the replication of research reported in a paper so difficult?
For AI, many factors affect their replicability. It is difficult to replicate a study as it requires access to and operational knowledge of software, data, specific settings (hyper parameters) and more. Another contributing factor is not technical but social: there is little incentive to spend time replicating someone else’s research. Researchers get no scientific credit for it and it costs time and uses resources while not contributing to their next promotion. While making the process of replication easier would be ideal, some indication of how replicable a published study is without actually having to replicate it, would already help. This is where various initiatives within the AI and wider computer science community are exploring how AI studies can be made more replicable.Determining the replicability of AI
During O. E. Gundersen’s recent talks at the AAAI; Reproducibility of AI workshop and, Evaluating Evaluation of AI Systems (Meta-Eval 2020), he provided a high level overview of methods used in AI research (Table 1).Table 1
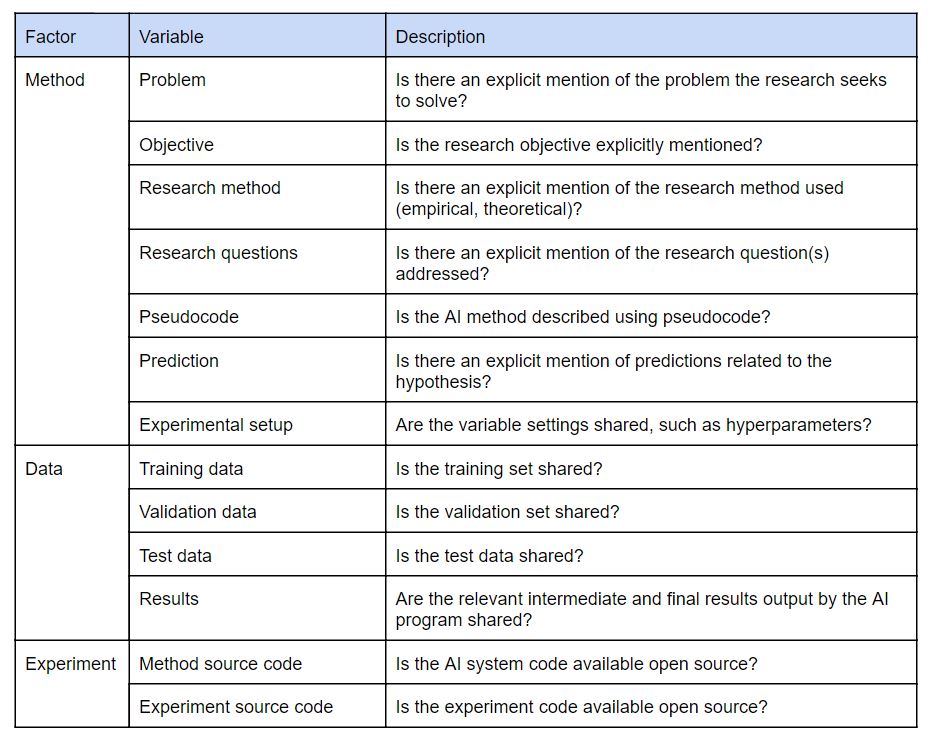
 Furthermore, Gundersen discussed the current state of replicability of AI research. One of his experiments investigated whether the presence of specific sections of a research paper could be used as a proxy to determine it’s replicability by classifying certain information in the methods, experiments and the data, see Table 2.
Furthermore, Gundersen discussed the current state of replicability of AI research. One of his experiments investigated whether the presence of specific sections of a research paper could be used as a proxy to determine it’s replicability by classifying certain information in the methods, experiments and the data, see Table 2.
Table 2
 O.E. Gundersen and Sigbjørn Kjensmo sampled 400 papers, 100 papers from each installment of AAAI 2014, AAAI 2016, IJCAI 2013 and IJCAI 2016, and assessed the documentation provided by each study, see Figure 1.
O.E. Gundersen and Sigbjørn Kjensmo sampled 400 papers, 100 papers from each installment of AAAI 2014, AAAI 2016, IJCAI 2013 and IJCAI 2016, and assessed the documentation provided by each study, see Figure 1.
Figure 1

Table 3
 O.E. Gundersen and Sigbjørn Kjensmo then sampled 30 of the most highly cited papers of these 400 based on Scopus data. They tried to replicate 22 papers after having filtered out those containing only a method section (R3 papers, see Table 3), and spent a maximum of 40 hours per paper. Categories of results after the expended effort were that they:
O.E. Gundersen and Sigbjørn Kjensmo then sampled 30 of the most highly cited papers of these 400 based on Scopus data. They tried to replicate 22 papers after having filtered out those containing only a method section (R3 papers, see Table 3), and spent a maximum of 40 hours per paper. Categories of results after the expended effort were that they:
- 20% Successfully replicated the research
- 13% Achieved partial success
- 23% Failed
- 17% Obtained no result
- 27% Were filtered out due to lack of data and experimental information
- Aspect of implementation not described or ambiguous (R2)
- Aspect of experiment not described or ambiguous (R2)
- Not all hyper-parameters are specified (R2)
- Mismatch between data in paper and available online (R1+R2)
- Method code shared; experiment code not shared (R1)
- Method not described with sufficient detail (R2)
References
Reproducibility vs. Replicability: A Brief History of a Confused Terminology, Hans E. Plesser, Front. Neuroinform., 18 Jan 2018 https://doi.org/10.3389/fninf.2017.00076 O. E. Gundersen’s presentation: https://folk.idi.ntnu.no/odderik/presentations/20200208-MetaEval-Keynote.pdf O. E. Gundersen and Sigbjørn Kjensmo. “State of the art: Reproducibility in artificial intelligence.” Thirty-second AAAI conference on artificial intelligence. 2018. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewFile/17248/15864 O. E. Gundersen, Yolanda Gil, and David W. Aha. “On reproducible AI: Towards reproducible research, open science, and digital scholarship in AI publications.” AI magazine 39.3 (2018): 56-68. https://doi.org/10.1609/aimag.v39i3.2816 O. E. Gundersen (2019). Standing on the Feet of Giants — Reproducibility in AI. AI Magazine, 40(4), 9-23. DOI:https://doi.org/10.1609/aimag.v40i4.5185 R. Isdahl and O. E. Gundersen, “Out-of-the-Box Reproducibility: A Survey of Machine Learning Platforms,” 2019 15th International Conference on eScience (eScience), San Diego, CA, USA, 2019, pp. 86-95. DOI: 10.1109/eScience.2019.00017AI Technology for People
Amsterdam Data Science (ADS) has created a tremendous network in which academia, companies, and the municipality come together in meetups and other events. Furthermore, its newsletter reports news from the community, and ADS seed projects encourage collaboration between research and companies. These are powerful means to build an ecosystem around data science, a field in which various disciplines have to come together to be successful and where fundamental research and application in real world settings go hand-in-hand.AI affecting the world in which we live
Recently ADS has added AI to their agenda and rightly so – AI is transforming the world at a very rapid pace. It builds upon the foundations laid out in big data research and data science. It introduces intelligence in the form of being able to really understand unstructured data such as text, images, sound, and video, and techniques for giving machines a form of autonomous behaviour. Over the last months the knowledge institutes in Amsterdam (AUMC, CWI, HvA, NKI, UvA, VU), in conjunction with Sanquin, the Amsterdam Economic Board and the City of Amsterdam, have formed a coalition and developed a joint proposition for AI in Amsterdam: “AI Technology for People” building upon three foundational themes.- Machine learning has been the main driver in the emergence of AI – and will continue to push it forward. Techniques include data-driven deep learning methods for computer vision, text analysis and search approaches that make large datasets accessible and knowledge representation and reasoning techniques to work with more human-interpretable symbolic information. Related activities include the analysis of complex organizational processes, and knowledge representation and reasoning techniques to work with symbolic information.
- Responsible AI is key to assuring that technology is fair, accountable and transparent (FAT). Methods need to prevent undesirable bias and all outcomes should be explainable through the identification of comprehensible parameters on which decisions are based. When high-impact decisions are involved, the reasoning behind them must be understandable to allow for ethical considerations and professional judgements.
- Hybrid intelligence combines the best of both of these worlds. It builds on the superiority of AI technology in many pattern recognition and machine learning tasks and combines it with the strengths of humans to deploy general knowledge, common sense reasoning and human capabilities such as collaboration, adaptivity, responsibility and explainability. Hereby combining human and machine intelligence to expand on human intellect rather than replace it. See the recent blog by Frank van Harmelen on the Hybrid Intelligence project.
The focus of AI Technology for People
The coalition focuses on three application domains.- AI for business innovation: As described in Max Welling’s blog, research excellence has already inspired several international partners to start research labs in Amsterdam within the Innovation Center for Artificial Intelligence (ICAI). Other companies, both regional and inter)national, continue to follow suit. Amsterdam hosts the headquarters of major companies that rely on AI to innovate, many small- and medium-sized high-tech AI businesses and a strong creative industry. The city provides an ideal ecosystem in which business innovations – both small and large – can flourish.
- AI for citizens: With its multitude of cultures, large numbers of tourists, rich history, criminal element and intense housing market, Amsterdam has all the challenges and opportunities of other major world cities, but in a far smaller area. With the excellent availability of open data in the city, AI can be applied directly to improve the well-being of citizens – with the city itself becoming a living lab.
- AI for health: The coalition is building on the work of renowned medical research organisations such as Amsterdam UMC, NKI, Sanquin and the Netherlands Institute for Neuroscience. The cross-sectoral health-AI collaboration has also been institutionalized in other ways, such as through ecosystem mapping and Amsterdam Medical Data Science meet-ups, with all initiatives being bundled under Smart Health Amsterdam.